Stable Diffusion 101


概括
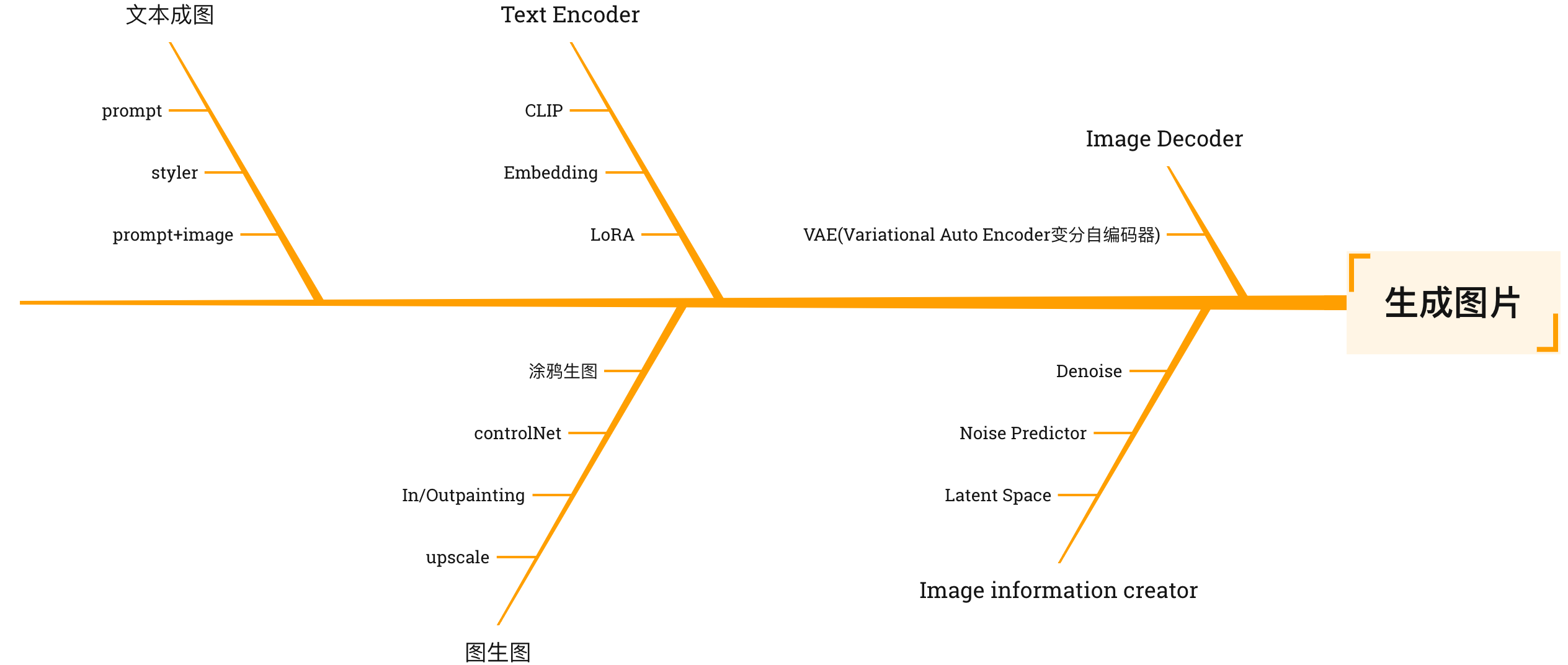
图像=stable diffusion(prompt)
入参prompt,通过函数stable diffusion,生成图像
Text Encoder(文本编译器)
将prompt编译成一个个词特征向量,即由数字表示的多位数组
CLIP(Contrastive Language Image Pre-training,对比语言图像预训练)
由Open AI开源,包含一个Text Encoder和一个Image Encoder,stable diffusion采用的是CLIP的Text Encoder
Image information creator
将特征向量和一张随机图转化到latent space中,降噪为符合指令的图片,此时仍是多维数组表示的特征向量
Image Decoder(图片解码器)
将latent space中的中间产物解码成一张图片
LoRA(Low-Rank Adaptation)
将参数注入到每一层函数中,不破坏原有的模型
Upscale
将低分辨率的图片转成高分辨率的图片
bicubic:双三次差值算法
bilinear:双线性法
nearest-exact:整数最邻近算法
基于训练后的模型进行放大
Inpainting
对不满意的区域进行修复
Outpainting
将原来的图片扩大,并填充内容
controlNet
通过图片的结构信息控制模型生成图片,相当于prompt的可视化,可以是一个草图、一个pose或者一个骨架图
总结